



Introduction
In today’s data-driven world, the ability to quickly find and utilize information is crucial for any business striving to maintain a competitive edge. Traditional search technologies often fall short when handling complex queries or vast databases. This is where AI steps in, transforming information retrieval through innovative techniques like Retrieval Augmented Generation (RAG).
RAG not only improves the efficiency of information retrieval but also the quality and relevance of the responses provided. In this blog, we will explore how RAG is revolutionizing the way businesses access and leverage their knowledge bases.
What is Retrieval Augmented Generation?
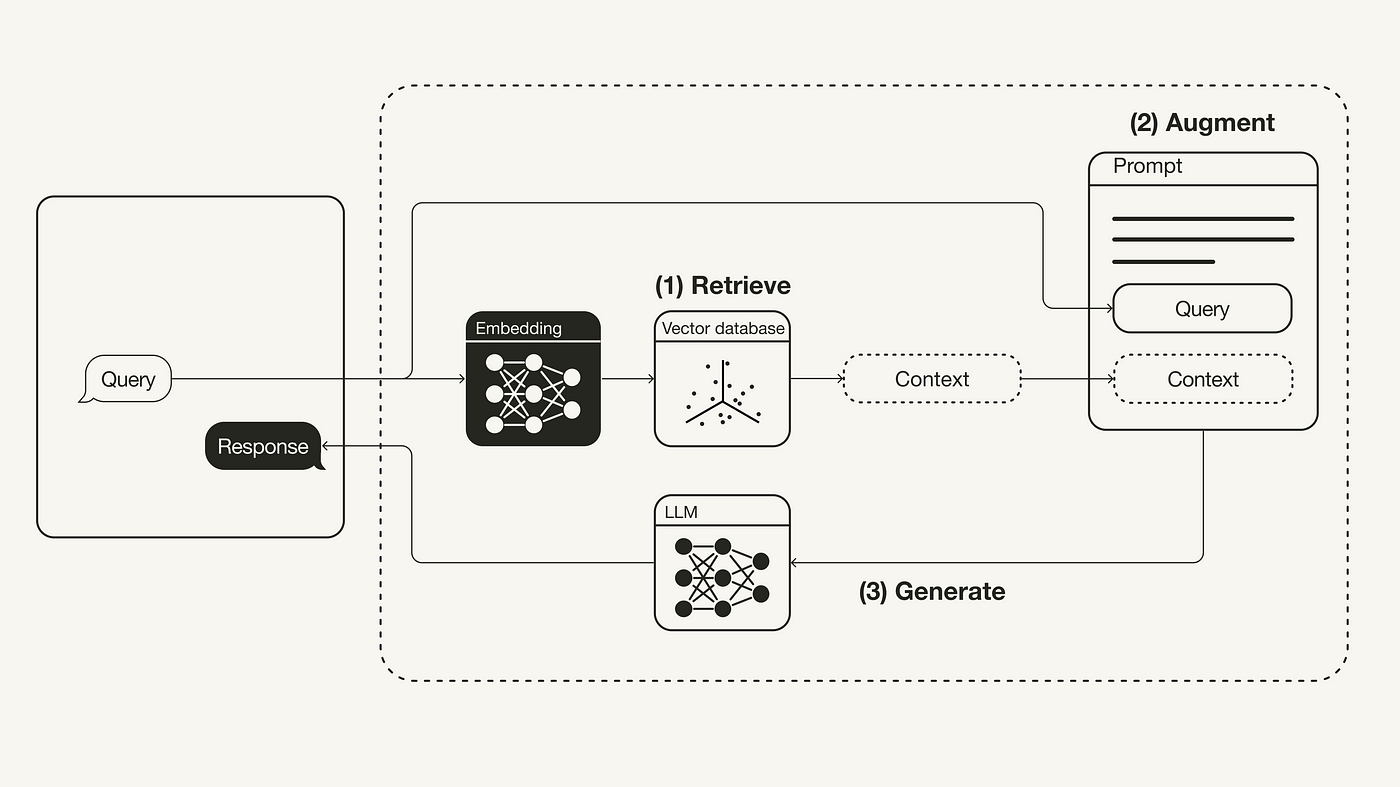
Retrieval Augmented Generation is a cutting-edge AI technique that enhances text generation tasks by integrating retrieval processes into the generation phase. Unlike conventional search algorithms that simply return documents based on keywords, RAG combines the capabilities of large-scale neural networks with sophisticated document retrieval to generate answers that are not just relevant but contextually enriched.
This technology employs two main components:
- Document Retrieval: First, RAG retrieves a subset of documents or data that might contain the information relevant to a query.
- Answer Synthesis: Then, it uses this retrieved information as a reference to generate coherent and accurate answers.
Key Components of RAG
Document Embeddings: At the heart of RAG are document embeddings—numerical representations of documents. These embeddings allow the model to compute and understand the similarity between different texts efficiently.
Query Processing: RAG processes natural language queries by converting them into the same embedding space as the documents. This ensures that the search for relevant information is both precise and context-aware.
Neural Networks and Transformers: Utilizing state-of-the-art neural networks, particularly transformer models, RAG can understand and generate human-like text based on the information retrieved.
Applications in Business
Enhanced Customer Support: RAG can provide customer service bots with the ability to fetch and synthesize answers from extensive help documents, improving response times and accuracy.
Knowledge Management: By allowing employees to access organizational knowledge bases with natural language queries, RAG helps in saving time and boosting productivity.
Compliance and Auditing: In industries where compliance is key, RAG facilitates quick retrieval of specific information, ensuring that all regulations are adhered to meticulously.
AI Models and Algorithms Powering RAG
1. Transformers and Neural Networks: At the core of RAG are transformer-based models. Transformers are a type of deep learning model that utilize mechanisms called attention and self-attention, which weigh the importance of different words in a sentence, irrespective of their position. This architecture makes them exceptionally good for understanding context in natural language processing tasks. Here are the main models:
2.Vector Databases: RAG systems heavily rely on vector databases to store and retrieve information efficiently. These databases use embeddings (vector representations of text) to quickly find the most relevant documents. Some of the specialized vector databases include:
- Pinecone: A managed vector database that makes it easy to build and scale vector search applications.
- Chroma DB: Another vector database that supports embedding and can perform fast vector similarity searches.
These databases allow RAG systems to operate at scale, handling large volumes of data while maintaining fast retrieval times.
Building a RAG System
Here’s a step-by-step guide on setting up a RAG system, tailored for understanding and practical implementation:
Step 1: Creating a Vectorized Database
Data Preparation: Start by collecting and preprocessing your documents. This involves cleaning the text (removing noise, standardizing format), and sometimes segmenting text into manageable parts.
Embedding: Use an AI model to convert texts into vector embeddings. Models like OpenAI’s embeddings API is typically used for this purpose. These embeddings capture the semantic meaning of texts in high-dimensional space.
Storage: Store these embeddings in a vector database (e.g., Pinecone or Chroma DB). This database will facilitate the fast retrieval of documents based on vector similarity.
Step 2: Query Processing
User Query Input: Receive a query from the user in natural language.
Query Vectorization: Convert the user query into a vector using the same model used for document embeddings. This ensures that both documents and queries share the same vector space, making it easier to compute similarities.
Step 3: Information Retrieval
Searching the Vector Database: Use the query vector to search the vector database for the most relevant document embeddings. The database returns the documents whose embeddings are closest to the query embedding, based on cosine similarity or another similarity metric.
Step 4: Answer Synthesis
Context Compilation: From the retrieved documents, compile the necessary context that will help in generating a precise answer.
Response Generation: Use a generative AI model (like GPT) to synthesize a coherent and contextually appropriate answer based on the retrieved information.
Step 5: Output
Deliver the Answer: Present the generated answer to the user. Optionally, refine the system’s future responses by incorporating user feedback.
Benefits of Retrieval Augmented Generation
The implementation of RAG in business environments offers several benefits:
Relevance and Accuracy: By leveraging relevant retrieved content to generate responses, RAG ensures high accuracy and context relevance in its answers.
Efficiency: RAG reduces the time employees spend searching for information, allowing them to focus more on decision-making and less on data hunting.
Scalability: As business data grows, RAG’s capabilities can be scaled to accommodate increased volumes without losing performance.
Challenges and Considerations
Data Quality and Quantity: Emphasize the importance of high-quality, well-organized data for effective retrieval.
Integration with Existing Infrastructure: Discuss potential challenges in integrating RAG with current IT systems and workflows.
Continual Learning and Updating: Highlight the need for ongoing updates and training to maintain the effectiveness and accuracy of the RAG system.
Case Study: PerfectApps AI Chatbot for Help Documentation Assistance
Overview
At Perfectapps, we are working on an AI Chatbot designed to assist users in navigating and understanding the company’s comprehensive help documentation. The AI Chatbot responds to user inquiries with specific information extracted from the manual, offering an interactive approach to problem-solving and learning.
Implementation
The AI Chatbot was integrated with Pinecone to handle the indexing of documentation for vectorized search. When users pose questions, the system employs a vector search to locate the most relevant sections of the documentation and then provides concise, accurate responses. This process bypasses the need for users to manually search through extensive documentation. We’re currently planning a beta release of the AI Chatbot in our upcoming Version 7.4 release.
Impact
We expect the implementation of the AI Chatbot in our PerfectApps no-code development platform to lead to several immediate benefits:
- User Empowerment: Users can directly ask the AI Chatbot for help, empowering them to solve problems independently without extensive manual searching.
- Time Efficiency: The AI Chatbot will reduce the time taken to find information, allowing users to focus more on productive tasks.
- Improved User Experience: The AI Chatbot will streamline the learning process, making it easier for users to understand and apply the features of PerfectApps to their custom built web app solutions.
Challenges
- Integration of RAG Process: Initially, the absence of a C# compatible version of LangChain presented a significant hurdle.
- Custom Solution Development: Transforming this challenge into an opportunity for innovation, our technical team devised a custom pipeline. This solution orchestrated the RAG workflow, from handling embeddings to interfacing with vector databases and utilizing chat models. It melded seamlessly with our existing C# framework, enabling us to leverage AI’s capabilities to enhance user interactions while maintaining our system’s robust performance.
- Seamless System Integration: This tailor-made solution was seamlessly integrated with our existing C# infrastructure, ensuring continuity and stability.
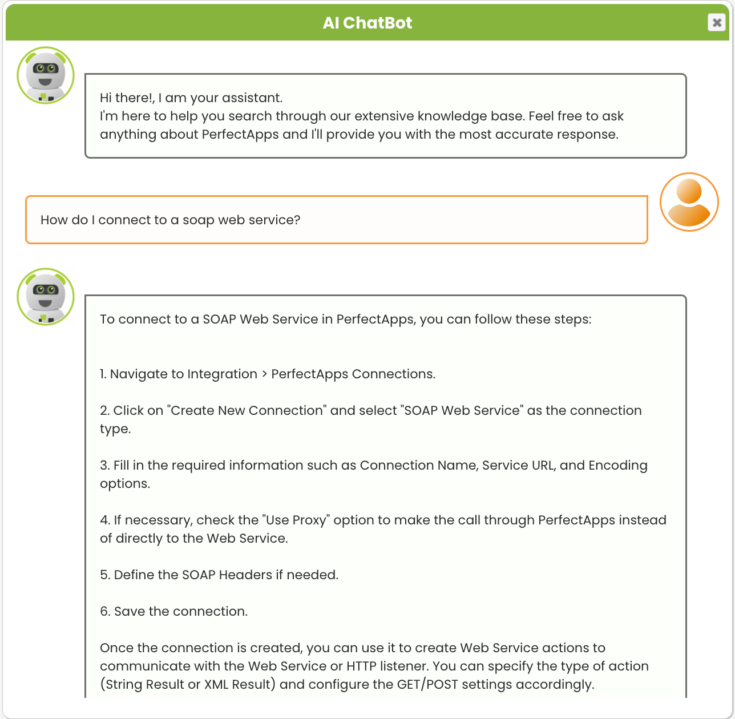
PerfectApps’ AI Chatbot stands as a practical example of AI’s role in enhancing user engagement with help documentation. By providing instant assistance, we expect the AI Chatbot to significantly improve users’ ability to utilize PerfectApps to its fullest, demonstrating a successful application of AI in user support and documentation management.
Conclusion
Retrieval Augmented Generation represents a significant leap forward in how businesses manage and retrieve information. By integrating advanced AI techniques with traditional retrieval methods, RAG provides enterprises with a powerful tool to enhance their information access and utilization, paving the way for smarter, faster business operations.